
NYUAD, Abu Dhabi — We spent the day thinking about what relevant data we could analyze. We had to decide what to write soon and were left scratching our heads because the possibilities seemed endless. After considering our options, we decided to take on a topic that thousands have deliberated on over the last two years: Covid-19-related misinformation. A collection of viruses known as Sars-CoV-2, or Covid-19, was responsible for a worldwide pandemic. In some way, this epidemic affected every country, industry, and individual. And now that the epidemic is nearing its end, we can properly evaluate the secondary components of this historical event, particularly those that no vaccine or medicine could prevent.
One of the most striking aspects of this pandemic was the simultaneous spread of both the disease and misinformation about it. While the pandemic spread quickly over the world, misconceptions about it circulated just as quickly on the internet. Countries with generally well-equipped health-care systems briefly collapsed due to the inability to treat so many afflicted citizens. Despite seeing close relatives succumb to the disease, many downplayed the matter and maintained themselves in isolated echo chambers.
But how can blatantly wrong information be accepted as the truth? Fake news would have faded away if it was based solely on fabricated stories, like other online conspiracies. Notwithstanding this, governments relied on misinformation campaigns to steer their policy throughout the pandemic because they were so convincing and effective. How did we get to this level? As all four of us come from countries heavily affected by the pandemic, we decided to dig deeper into the issue of Covid-19-related misinformation. According to a study on misinformation, six elements make fake news especially attractive to the public:
Why and when are fake news attractive?
According to the paper "The psychological drivers of misinformation belief and its resistance to correction", fake news rely on psychological factors to be popular, and even after being dismissed, they still affect your decision-making process. The factors that make fake news popular are the following:

Intuitive thinking: Fake news are easy to digest and interpret, and they do not leave space for discussion or critical thinking.

Cognitive Failure: When we consume news, it is common to focus on the content rather than on the sources or implications. This includes forgetting that we already saw the news' retraction, which means that we use misninformation even after learning and agreeing that it is fake.

Illusory Truth: to make fake news more credible, the reports should look familiar and repeated. After being drove to believe that the world agrees with the fact, it is much easier to embrace it.

Source Cues: Unlike fact-checked news, whose main sources are organizations and specialists directly studying the matter, fake news appeal to popular authority figures or have no source at all, but they always create a us x them situation where everyone in your group seems to agree with the misinformation and the enemy group is responsible for all the problems in the world, no matter what this group is.

Emotion: Our brain tends to easily remember emotional responses rather than pure facts. Memories linked to strong emotions such as anger, euphory or gloom are harder to ignore. Misinformation sites purposedly weaponize this creating fearmongering or mockery content with loose ties to reality. This way, fake news look more relevant and easy to recall.

Worldview: Fake news work with the confirmation bias combined with conspiracy theories. The brain rewards reading content that agrees with preconcieved information since it means that you are aligned with you community's thoughts. For this reason, msiinformation can be contradictory, but the conclusion will always appeal to your ego confirming what you think.
How to identify fake news?
Upon reading the paper, it became easier to understand how fake news could become so popular. Misinformation manipulated the ego of millions, who accordingly acted recklessly, which allowed the virus to spread rapidly among the populace. And, unfortunately, even after understanding that something is false, people frequently use that knowledge to make decisions.
Although the predicament was grim, our newly formed group asked: What can we do? If fake content seemed hard to dissociate from, maybe we needed to know how to identify misinformation in a way independent of the content. Also, legitimate information has not been as effective in fighting for space in popular beliefs. Perhaps most official sources were missing some of the factors that made misinformation popular. Such questions point us to one thesis: fake news propagation is fundamentally different from mainstream tested information, not only in content but also in form, in perceptible and imperceptible ways.
Government regulations kept getting relaxed as the numbers declined. We had a direction to follow and we finally had a thesis. The question now was what to look for and how to find it? Misinformation databases were easy to find because of the sheer volume of damaging content on the internet. While factual news commonly appears under articles and mainstream media sites, fake news tends to spread on social media. This difference implies that they have different constraints even when there is no variation in content. The number of characters used, the level of formality, and the quality of sources are strikingly different between a successful article and a popular tweet. If we were not careful, we would detect differences that exist due to the channel used to transmit information rather than the context and content. For this reason, we decided to invest time in social media content, English-speaking Twitter specifically, as they are home to a large volume of misinformation and fact-checked news trying to dominate the space.
Our initial problem was deciding which type of content to evaluate. We originally intended to examine long-form English articles. The database we found had links to both real and fake news stories. While there were many links to long-form pieces, many of those links were either defunct or linked to fact-checking websites that did not provide links to the source material. After a bit more digging, we uncovered a thorough dataset compiled by independent researchers for the Association for the Advancement of Artificial Intelligence (AAAI) to classify tweets into true news and misinformation. We also filtered out English tweets from Princeton’s ESOC COVID-19 Misinformation Dataset, used the Twitter API to scrape their text, and added them to the false news database. Now, we had over 3000 true tweets and over 3000 false tweets to analyze.
First, we wanted a quick overview of our datasets to ascertain some immediate differences between true tweets and misleading ones. First, we performed steps to remove stopwords such as ‘and’ or ‘he’, make everything lowercase, and combine versions of words such as ‘dying’, ‘died’, and ‘die’ into a single word - ‘die’. Going into the analysis, we expected that true tweets would contain more facts regarding the number of cases and reported deaths, while fake tweets would contain stronger, more assertive language to shift the blame of the disease's destruction on the "other" group or political party. As such, we looked at the words most frequently used across both true and misleading tweets. To dive in deeper, we used a technique known as LDA Topic Modelling, that helped us discover the common broad topics the datasets seemed to cover.
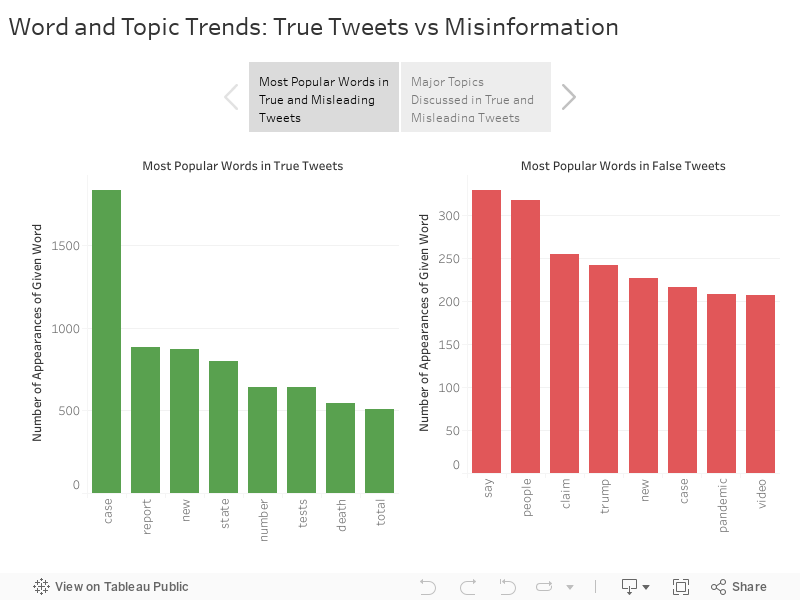
≺br>
Much like we expected, words like ‘case’ and ‘report’ abounded in the true dataset, whereas the fake dataset contained stronger words such as ‘claim’, and the name of the former U.S. president ‘Trump’. The topic models also showed us interesting clusters of information, and we realized facts like perhaps a large amount of our data was taken from an Indian audience. Overall, the topic models showed us an important and perceptible way how misinformation was different from true information: the difference lay in the content itself. Now, we wanted to go further.
We had seen from experience the power of fear-mongering and enraging content. Manipulating feelings was an old tactic for social media, and Facebook even revealed to engage users by making them angry in leaked papers. Whether one agreed with the content or not, they would pay attention to it and share it with others. It is a win-win situation for the publisher, and the only way to stop it is by using the old internet adage "do not feed the trolls." But for us trying to identify fake content, this rage is also very useful. Some tools classify text according to its supposed emotional content. They work by assigning values to words according to content pre-classified by humans. The first tool we tested was a sentiment analysis algorithm, which seems like an oxymoron the first time you hear about it. The one we used classifies text between positive, negative, or neutral by giving values to each word in the text. While we initially expected tweets to be too short to conduct such analysis on, we discovered this had been done before successfully. Starting now, we expected more negative content under the fake news database and more neutral tones in the truthful set. This is what we found:
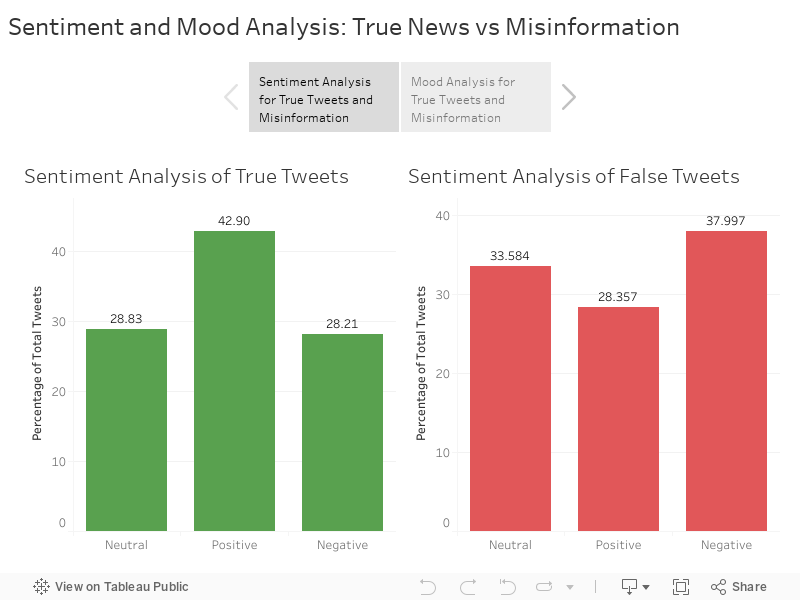
As we hoped, there was a clear difference between true tweets and misleading ones in terms of the sentiments they were associated with. Tweets are short, with a limit of 280 characters. Although we found a pattern, shorter texts do not provide results as reliable as long articles. Better analyses necessitate better data, which is inherent in statistics. In order to acquire a better grasp of the emotional characteristics of various tweets, we opted to use Mood Analysis, which instead of categorizing tweets as positive or negative, categorizes the mood that the tweet conveys. This technique has also been used previously to show important results based just on analyzing tweets. We employed a mood analysis algorithm that categorized the mood into six categories: fatigue, vigor, confusion, tension, anger, and depression. Surprisingly, the results for this analysis turned out to be pretty much the same for both datasets. The greatest number of tweets were classified as "depression" in both classifications, which is to be expected considering how gloomy the pandemic has been. A large number of tweets may be labeled "depressing" because of the prevalence of grim words such as "death", "die" and so on. However, the similar distributions in this analysis, when compared to our initial sentiment analysis, go to show that the research needs more work, and a lot of the results come down to the different ways similar algorithms work.
When it comes to misinformation consumption, a common but dubious claim is that misinformation consumption is associated with low levels of education. Since it is plausible that misinformation may have less jargon to make it accessible to more people, we decided to put this hypothesis to the test. We used the LIX index to evaluate how difficult a text is to comprehend. The LIX index examines word and sentence length and assigns a value to a text without taking its content into account. As a measure of readability, we also compared the true and false tweets on factors such as word count, average word length, and % of unique words.
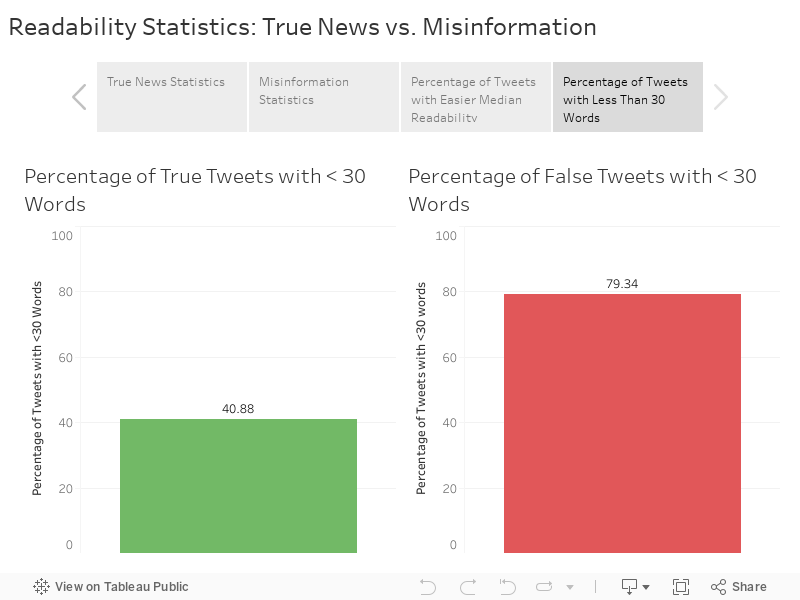
We discovered the most interesting results when looking at word counts, where the number of fake tweets having less than 30 words was almost double the number of true tweets for the same criteria. This could potentially mean that fake tweets were designed to be shorter for a purpose, whereas true tweets would attempt to present all the information. Similarly, the % of unique words also showed a significant difference. Other factors such as the LIX index, however, showed quite similar results. We realized that this could have been since Tweets in general are quite similar to each other in the factors the LIX index considered. In our search for possible reasons, we found a study that compared results from readability indices and labels given by users having English as their second language, that found exactly that.
Moving on, we tried to come up with even more factors. We had done the textual analysis but missed the fact that since tweets have a restriction on the number of characters used, there are other ways to transmit information in this limited environment. Specifically, tweets were different than normal texts in the fact that they made extensive use of parts such as ‘@’s when mentioning someone, ‘#’s when discussing a topic, hyperlinks when redirecting somewhere else, and emojis when trying to express an emotion.
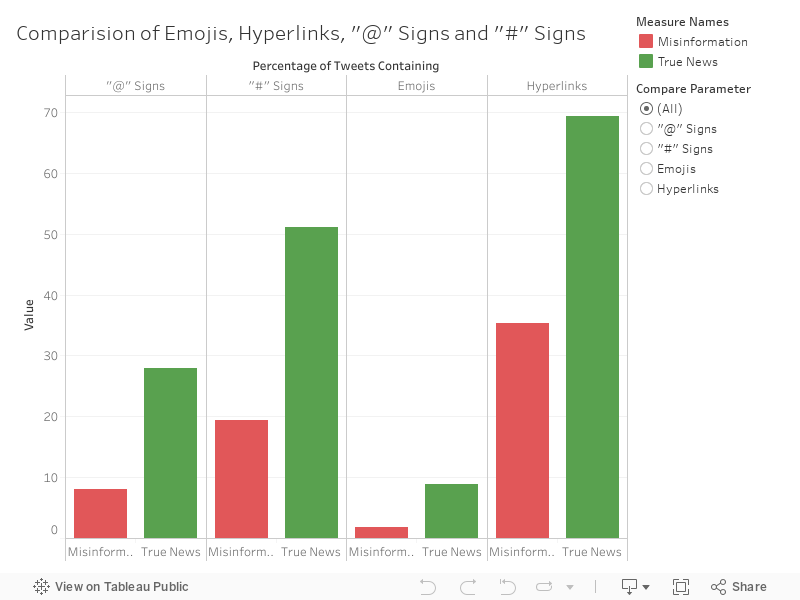
Our analysis showed that true news is much more likely to contain all emojis, hyperlinks,’#’s, and ‘@’s. The use of emojis (primarily, number or arrow ones) by news outlets to list various facts linked to Covid-19 cases and testing could be ascribed to this. It's also possible to explain the abundance of hyperlinks in (true) tweets by pointing out that true tweets tend to end with links to the news stories or articles on the news channel’s official website. True tweets also contain ‘@’ signs more frequently, primarily because they tag the author of the news article in the tweet itself. We could not find a similar logic for the comparatively larger number of ‘#’s present in true tweets, but we believe that a deeper analysis can find an answer to that question.
Let’s take a step back and reflect on what we have seen so far. We saw differences between true tweets and misinformation for the various factors we investigated, but were these findings significant? These differences could have arisen purely by chance. How can we guarantee that what we found just did not happen by accident? Although we can never be sure, math comes to help in making those decisions. We employed hypothesis testing using various methods such as F-testing for the linear regression coefficients and z-tests for the quantitative series of data we have gathered to examine whether the differences observed between true tweets and misinformation are statistically significant. For the most part, our findings showed us that… Yes! The differences between true tweets and misinformation were indeed significant, with the only exception arising in the case of average word length, which showed a surprisingly similar distribution between fake and true news. Just to add, the results for the mood analysis were qualitative and visually too similar to suggest further searching for variation.
As the deadline drew closer, a mix of hope and desperation drew upon us. The differences between true and misleading tweets that we had found seemed highly interesting, but what if we could combine them to predict which tweets were true, and which were misleading? To do this, we decided on using two techniques known as linear regression, and logistic regression. These techniques take in some data, its parameters and its labels, and then try to form predictions on other similar data. We used a little over 75% of our tweets to train our two algorithms, and 25% to test the accuracy of our predictions. The results we achieved were surprisingly promising.
On setting the right threshold, linear regression classified 80% of the fake tweets as fake, and 68% of the true tweets as true. Logistic regression gave us even better results, with 81% of fake tweets correctly classified, and 80% of the true ones correctly identified. This observation does indicate that our observed factors enable us to differentiate between true tweets and misinformation to a large extent. This brings us full circle, back to our main idea that beyond the content of the tweets itself, there are differences between true tweets and misinformation, there are perceptible and imperceptible differences — which helped us classify them with good accuracy.
However, there is a caveat to keep in mind: as more and more information is discovered, fact-checked data can become misleading. No matter how well we choose our sources, we are bound to find fake news published as reliable information. Outdated information may skew our findings since its goal is not to mislead when created, but it will still arise as fake after being fact-checked.
As we come to the end of this project, the whole semester returns to our minds. Throughout this project, we have faced several challenges and learned about the designs of misinformation and the power of data. Through data, we were able to expose the perceptible and imperceptible differences between fake and true tweets. At the same time, it is important to critically analyze what we consume, much like how we realized that several factors we expected to make a difference, actually did not. At the end of the day, we believe our project is a symbol of how data can empower everyone to generate incredible insights about the world around them, and with its power, all of us can help change the world.